The Hidden Auditory Knowledge Inside Language Models
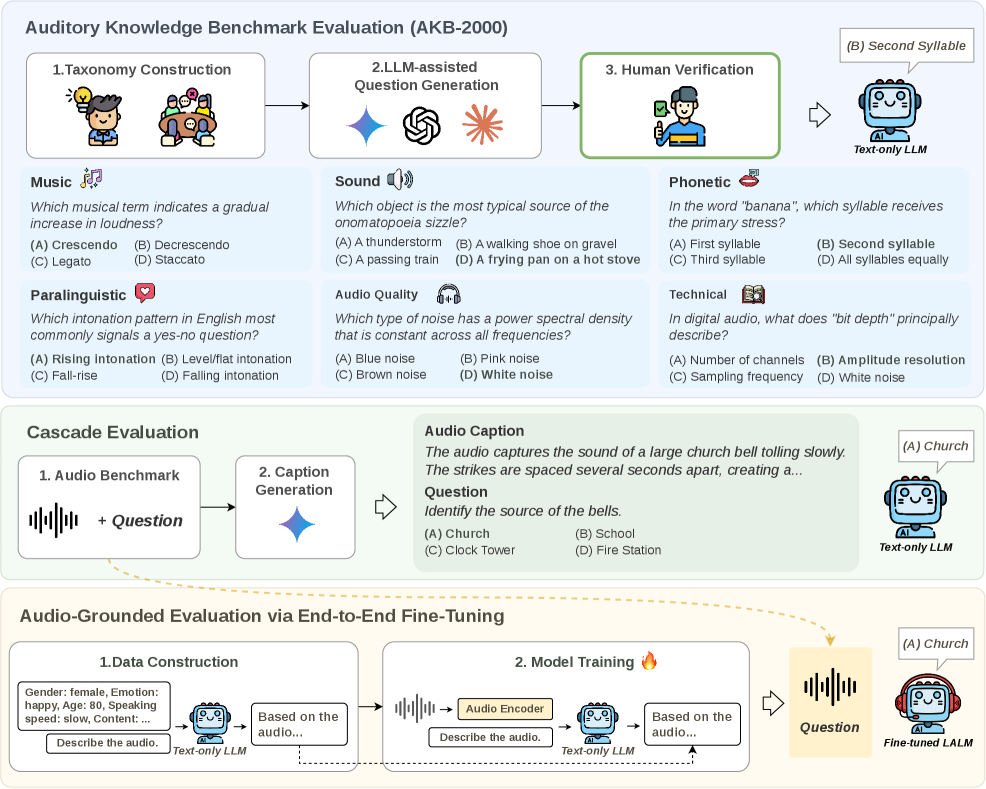
Text-only LLMs may already know enough about sound to predict downstream audio model performance before an encoder is ever attached.
Text-only LLMs may already know enough about sound to predict downstream audio model performance before an encoder is ever attached.
![The Mechanics of Steins Gate (2023) [pdf]](https://source.unsplash.com/800x600/?mechanics,steins,gate)




